

One of our customers had a requirement of copying data that was locked in an Azure Databricks Table in a specific region (let’s say this is eastus region). The tables were NOT configured as Delta tables in the originating region and a subset of personnel had access to both the regions.
However, the analysts were using another region (let’s say this is westus region) as it was properly configured with appropriate permissions. The requirement was to copy the Azure Databricks Table from eastus region to westus region. After a little exploration, we couldn’t find a direct/ simple solution to copy data from one Databricks region to another.
One of the first thoughts that we had was to use Azure Data Factory with the Databricks Delta connector.  This would be the simplest as we would simply need a Copy Data activity in the pipeline with two linked services. The source would be a Delta Lake linked service to eastus tables and the sink would be another Delta Lake linked service to westus table. This solution faced two practical issues:
This would be the simplest as we would simply need a Copy Data activity in the pipeline with two linked services. The source would be a Delta Lake linked service to eastus tables and the sink would be another Delta Lake linked service to westus table. This solution faced two practical issues:
- The source table was not a Delta table. This prevented the use of Delta Lake linked service as source.
- When sink for copy activity is a not a blob or ADLS, it requires us to use a staging storage blob. While we were able to link a staging storage blob, the connection could not be established due to authentication errors during execution. The pipeline error looked like the following:
Operation on target moveBlobToADB failed: ErrorCode=AzureDatabricksCommandError,Hit an error when running the command in Azure Databricks. Error details: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Unable to access container adf-staging in account xxx.blob.core.windows.net using anonymous credentials, and no credentials found for them in the configuration. Caused by: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Unable to access container adf-staging in account xxx.blob.core.windows.net using anonymous credentials, and no credentials found for them in the configuration. Caused by: hadoop_azure_shaded.com.microsoft.azure.storage.StorageException: Public access is not permitted on this storage account..On digging deeper, this requirement is documented as a prerequisite. We wanted to use the Access Key method but it requires the keys to be added into Azure Databricks cluster configuration. We didn’t have access to modify the ADB cluster configuration.
To work with this, we found the following alternatives:
- Use Databricks notebook to read data from non-Delta Tables in Databricks. The data can be stored in a staging Blob Storage.
- To upload the data into the destination table, we will again need to use a Databricks notebook as we are not able to modify the cluster configuration.
Here is the solution we came up with:
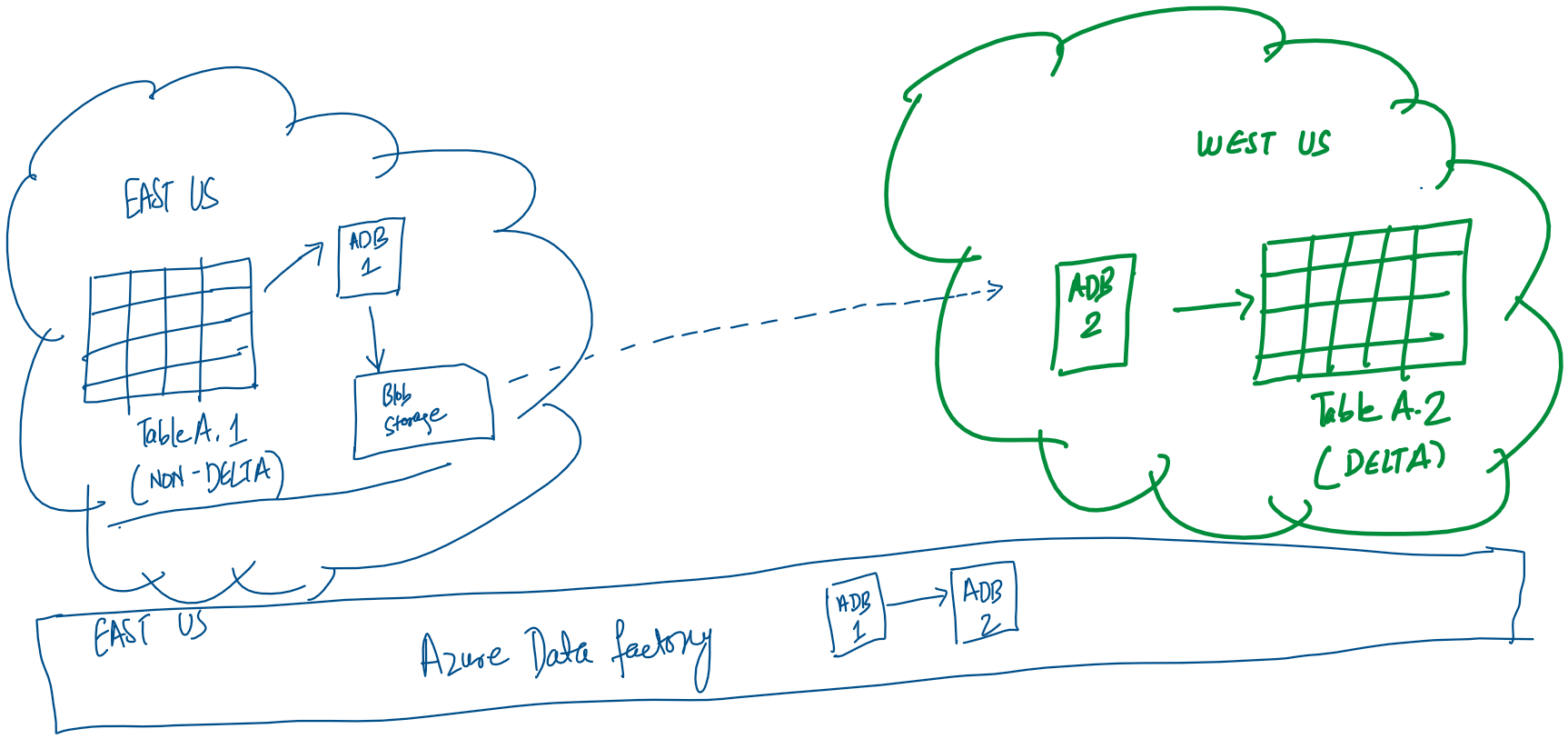
In this architecture, the ADB 1 notebook is reading data from Databricks Table A.1 and storing it in the staging blob storage in the parquet format. Only specific users are allowed to access eastus data tables, so the notebook has to be run in their account. The linked service configuration of the Azure Databricks notebook requires us to manually specify: workspace URL, cluster ID and personal access token. All the data transfer is in the same region so no bandwidth charges accrue.
Next the Databricks ADB 2 notebook is accesses the parquet file in the blob storage and loads the data in the Databricks Delta Table A.2.
The above sequence is managed by the Azure Data Factory and we are using Run ID as filenames (declared as parameters) on the storage account. This pipeline is configured to be run daily.
The daily run of the pipeline would lead to a lot of data in the Azure Storage blob as we don’t have any step that cleans up the staging files. We have used the Azure Storage Blob lifecycle management to delete all files not modified for 15 days to be deleted automatically.
