Generative AI (GenAI) tools — from ChatGPT and Gemini to Claude — are no longer just innovation experiments. They’re embedded in workflows, customer journeys, and enterprise applications.
But with that opportunity comes a sharp reality: GenAI introduces new data privacy risks that most corporate systems were never designed to handle.
This article breaks down:
- The top privacy challenges organisations face when adopting GenAI.
- What enterprise-grade solutions offer to mitigate these risks.
- Practical steps for enterprises and project managers to operationalise GenAI safely.
Why Privacy Matters More Than Ever
GenAI thrives on data — but that’s exactly where its risk lies. Every prompt, document, or snippet entered could become a data-governance concern.
The Core Privacy Risks
| Risk | What It Means | Why It Matters |
|---|---|---|
| Data Leakage & Unintended Exposure | Employees may paste sensitive (PII) or proprietary data into public GenAI tools, losing control once it leaves the org boundary. | Studies (Deloitte) show 75% of tech professionals rank privacy as a top GenAI concern. |
| Unintended Model Training | Non-enterprise versions may use user inputs for model improvement. | Proprietary IP could be absorbed into shared models. |
| Ownership & Retention Ambiguity | Consumer tools often lack clarity on who owns prompts and outputs or how long data is stored. | Creates legal uncertainty around IP and auditability. |
| Regulatory Compliance Gaps | GenAI usage must align with GDPR, CCPA, and emerging AI Acts. | Non-compliance risks penalties and reputation loss. |
| Shadow IT & Unapproved Usage | Employees may use personal GenAI accounts. | Creates blind spots for data exposure and audit gaps. |
Bottom Line: GenAI amplifies traditional data risks — because the data flows are richer, models more opaque, and control boundaries blur faster.
The Solution: What It Looks Like
The solution lies in ensuring that GenAI tools respect the data privacy of the documents uploaded. The way GenAI tools have struck a balance is to offer “privacy” as a feature in their enterprise editions.
When enterprises upgrade to enterprise editions of GenAI tools, they gain visibility, ownership, and control. Let’s examine OpenAI’s enterprise commitments as an example blueprint.
1. Ownership & Control of Data
“You own and control your data. We do not train our models on your business data by default.” — OpenAI Enterprise Privacy
✅ Inputs and outputs remain your property.
✅ You control data retention.
✅ No auto-training on business data.
Why it matters:
Enterprises retain IP rights, reduce legal ambiguity, and align with data-minimisation and right-to-erasure principles.
2. Fine-Grained Access & Authentication
- SAML-based SSO integration
- Admin dashboards to control who can access what
- Connector governance to approve or restrict data sources
Why it matters:
Access governance limits who can interact with sensitive data — and how. Permissions reduce accidental or malicious data exfiltration.
3. Security, Compliance & Certifications
- AES-256 encryption at rest; TLS 1.2+ in transit
- SOC 2 Type II certification
- BAA & DPA support for regulated sectors (e.g., healthcare, finance)
Why it matters:
Aligns GenAI use with enterprise IT standards and compliance requirements.
4. Data Retention & Deletion Controls
“Admins control retention. Deleted conversations are removed within 30 days.” — OpenAI
- Zero-Data-Retention (ZDR) for API endpoints
- Custom deletion timelines
Why it matters:
Enables compliance with right-to-erasure laws and reduces long-term data exposure risk.
5. Model Training & Fine-Tuning Controls
- No business data used for training without explicit opt-in.
- Fine-tuned models remain exclusive to the enterprise.
Why it matters:
Prevents proprietary data from bleeding into shared models. Protects confidential business logic and datasets.
Translating Commitments into Enterprise Practice
Here’s how to operationalise privacy-by-design in your GenAI strategy.
| Step | Action | Why It Matters |
|---|---|---|
| 1 | Create a “What Goes into GenAI” Policy | Ban sensitive data (PII, source code, contracts) unless approved. |
| 2 | Use Enterprise Licenses | Ensure tools provide encryption, retention control, and no auto-training. |
| 3 | Govern Connectors | Limit which internal systems feed into GenAI tools. |
| 4 | Define Retention Rules | Configure retention periods and deletion workflows. |
| 5 | Monitor Usage | Use compliance APIs to track prompts, access logs, and connectors. |
| 6 | Train Employees | Reinforce responsible usage and red-flag categories (finance, HR, IP). |
| 7 | Align with Legal & Governance Policies | Map GenAI practices to your data-governance framework and DPIAs. |
| 8 | Use ZDR Endpoints for Sensitive Data | Required for regulated or confidential workloads. |
| 9 | Review Regularly | Re-audit tools and contracts as regulations evolve. |
Applying It to Your Context: ERP & Project Management
For ERP implementations — where financial, HR, and vendor data converge — the stakes are higher.
- Data boundaries: Never use GenAI with live financial or payroll data unless the endpoint is enterprise-secured.
- Vendor contracts: Ensure client or third-party NDAs don’t prohibit AI-based processing. Include a section that mentions that contracts may be reviewed by GenAI tools.
- Governance embedding: Add GenAI checkpoints in your project governance map — who approves prompts, what is logged, how outputs are validated.
- Audit readiness: Maintain GenAI usage logs — prompt, purpose, output, approver.
- Model isolation: When fine-tuning internal GenAI workflows, use isolated models to prevent cross-project exposure.
The Takeaway
Generative AI unlocks speed and scale, but data privacy is the cost of entry for responsible adoption.
Enterprise GenAI tools — like OpenAI’s ChatGPT Enterprise — now offer the controls and transparency needed for compliant, secure innovation. Yet, technology alone isn’t enough.
Enterprises must also embed:
- Governance (policies & audits)
- Awareness (training & culture)
- Alignment (legal & regulatory frameworks)
For project managers and IT leaders, the mission is clear:
👉 Innovate boldly, govern responsibly, and ensure that data privacy remains the cornerstone of your GenAI strategy.













 Save and exit.
Save and exit.





 The Indian government has recently passed the
The Indian government has recently passed the 




















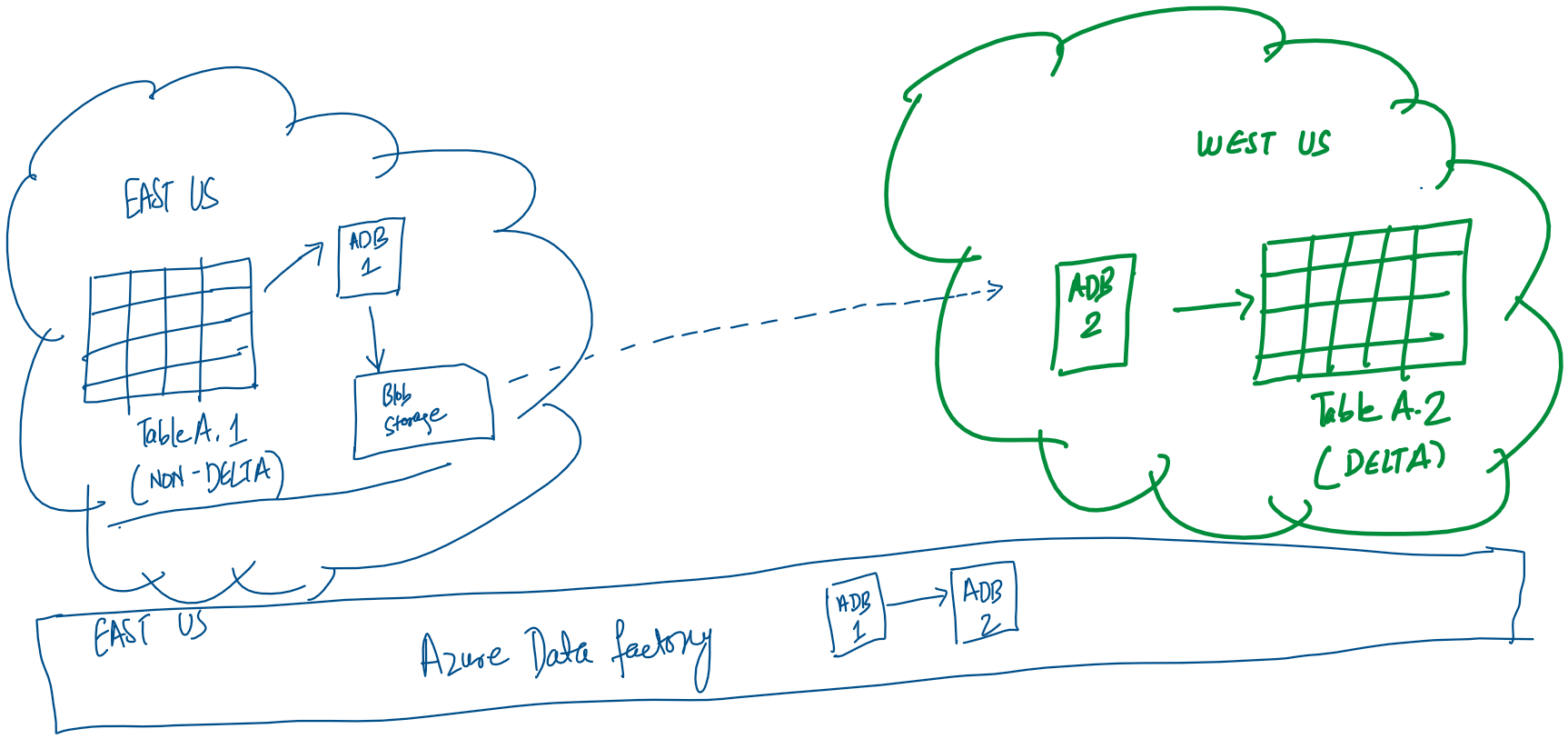
 This would be the simplest as we would simply need a Copy Data activity in the pipeline with two linked services. The source would be a Delta Lake linked service to eastus tables and the sink would be another Delta Lake linked service to westus table. This solution faced two practical issues:
This would be the simplest as we would simply need a Copy Data activity in the pipeline with two linked services. The source would be a Delta Lake linked service to eastus tables and the sink would be another Delta Lake linked service to westus table. This solution faced two practical issues: