In the earlier post, we went over some concepts regarding Machine Learning done with Spark ML. Here are primarily 2 types of objects relating to machine learning we saw:
- Transformers: Objects that took a DataFrame, changed something in it and returned a DataFrame. The method used here was “transform”.
- Estimator: Objects that are passed in a DataFrame and would apply an algorithm on it to return a transformer. E.g. GBTClassifier. We used the “fit” function to apply the algorithm on the Dataframe.
In our last example of predicting income level using Adult dataset, we had to change our input dataset to a format that is suitable for machine learning. There was a sequence of changes we had done e.g. converting categorical variables to numeric, One Hot Encoding & Assembling the columns in a single column. Everytime there is additional data available (which will be numerous times), we will need to do these steps again and again.
In this post, we will introduce a new Object that organises these steps in sequence that can be run as many times as needed and it is called the Pipeline. The Pipeline chains together various transformers and estimators in sequence. While we could do the machine learning without the Pipeline, it is a standard practice to put the sequence of steps in a Pipeline. Before we get there, let’s try to add an additional step in fixing our pipeline and that is to identify and remove Null data. This is indicated in our dataset as ‘?’.

To know how many null values exist let’s run this command:
from pyspark.sql.functions import isnull, when, count, col
adultDF.select([count(when(isnull(c), c)).alias(c) for c in adultDF.columns]).show()
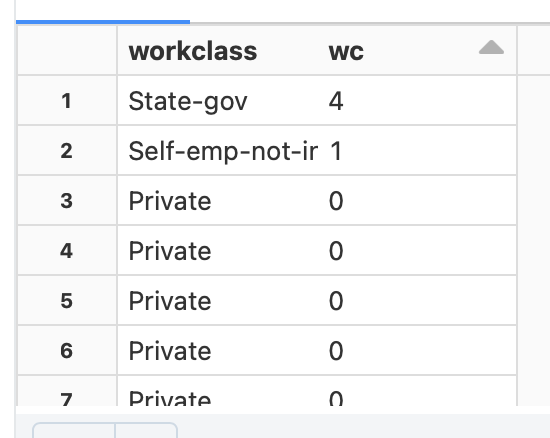
The result shows that there are no null values. Inspecting the data, we see that null values have been replaced with “?”. We would need to remove these rows from our dataset. We can replace the ? with null values as follows:
adultDF = adultDF.replace('?', None)
Surprisingly this doesn’t change the ? values. It appeared that the ? is padded with some spaces. So we will use the when and trim function as follows:
from pyspark.sql.functions import isnull, when, count, col,trim
adultDF = adultDF.select([when(trim(col(c))=='?',None).otherwise(col(c)).alias(c) for c in adultDF.columns])This replaces ? will null that we can now drop from our dataframe using dropna() function. The number of rows remaining are now 30,162.
Now let’s organise these steps in a Pipeline as follows:
from pyspark.ml import Pipeline
adultPipeline = Pipeline(stages = [wcindexer,eduindexer,maritalindexer,occupationindexer,relindexer,raceindexer,sexindexer,nativecountryindexer,categoryindexer,ohencoder,colvectors])The stages list contains all the transformers we used to convert raw data into dataset ready for machine learning. This includes all the StringIndexers, OneHotEncoder and VectorAssembler. Next, the process of defining the GBTClassifier and BinaryClassificationEvaluator remains the same as in the earlier post. You can now include the GBTClassfier in the pipeline as well and run the fit() on this pipeline with train dataset as follows:
adultMLTrainingPipeline = Pipeline(stages = [adultPipeline,gbtclassifier])
gbmodel = adultMLTrainingPipeline.fit(train)However, we can perform another optimization at this point. The model currently trained is based of a random split of values from the dataset. Cross Validation can help generalise the model even better by determining best parameters from a list of parameters and do it by creating more than one train and test datasets (called as folds). The list of parameters are supplied as ParamGrid as follows:
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
paramGrid = ParamGridBuilder()\
.addGrid(gbtclassifier.maxDepth, [2, 5])\
.addGrid(gbtclassifier.maxIter, [10, 100])\
.build()
# Declare the CrossValidator, which performs the model tuning.
cv = CrossValidator(estimator=gbtclassifier, evaluator=eval, estimatorParamMaps=paramGrid)The cross validator object takes the estimator, evaluator and the paramGrid objects. The pipeline will need to be modified to use this cross validator instead of the classifier object we used earlier as follows:
adultMLTrainingPipeline = Pipeline(stages = [adultPipeline,gbtclassifier])
adultMLTrainingPipeline = Pipeline(stages = [adultPipeline,cv])With these settings, the experiment ran for 22 mins and the evalution result came out to be 91.37% area under RoC.